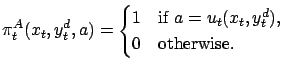In this subsection we review a particular controller for continuous dynamical systems, the static and dynamic state (SDS) feedback controller proposed by Lorincz and colleagues [Szepesvári et al.(1997),Szepesvári and Lorincz(1997)], for more details see the Appendix. It is shown that it can be easily inserted into the E-learning scheme.
The SDS control scheme gives a solution to the control problem
called speed field tracking5 (SFT) in continuous dynamical systems
[Hwang and Ahuja(1992),Fomin et al.(1997,Szepesvári and Lorincz(1998)].
The problem is the following. Assume that a state space ![]() and a
velocity field
and a
velocity field
![]() are given. At time
are given. At time ![]() , the
system is in state
, the
system is in state ![]() with velocity
with velocity ![]() . We are looking for a
control action that modifies the actual velocity to
. We are looking for a
control action that modifies the actual velocity to ![]() .
The obvious solution is to apply an inverse dynamics, i.e., to
apply the control signal in state
.
The obvious solution is to apply an inverse dynamics, i.e., to
apply the control signal in state ![]() which drives the system
into
which drives the system
into ![]() with maximum probability:
with maximum probability:
Of course, the inverse dynamics
![]() has to be
determined some way, for example by exploring the state space
first.
has to be
determined some way, for example by exploring the state space
first.
The SDS controller provides an approximate solution such that the
tracking error, i.e.,
![]() is bounded, and this
bound can be made arbitrarily small. This represents considerable
advantage over approximations of the inverse dynamics, which can
be unbounded and therefore may lead to instabilities when used in
E-learning.
is bounded, and this
bound can be made arbitrarily small. This represents considerable
advantage over approximations of the inverse dynamics, which can
be unbounded and therefore may lead to instabilities when used in
E-learning.
Studies on SDS showed that it is robust, i.e., capable of solving
the SFT problem with a bounded, prescribed tracking error
[Fomin et al.(1997),Szepesvári et al.(1997),Szepesvári and Lorincz(1997),Szepesvári(1998)].
Moreover, it has been shown to be robust also against perturbation
of the dynamics of the system and discretization of the state
space [Lorincz et al.(2002)]. The SDS controller fits real
physical problems well, where the variance of the velocity field
![]() is moderate.
is moderate.
The SDS controller applies an approximate inverse dynamics
![]() , which is then corrected by a feedback term (for the
sake of convenience, we use the shorthand
, which is then corrected by a feedback term (for the
sake of convenience, we use the shorthand
![]() ). The
output of the SDS controller is
). The
output of the SDS controller is
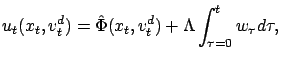
The above described controller cannot be applied directly to
E-learning, because continuous time and state descriptions are
used. Therefore we have to discretize the state space, and this
discretization should satisfy the condition of `sign-properness'.
Furthermore, we assume that the dynamics of the system is such
that for sufficiently small time steps all conditions of the SDS
controller are satisfied.7 Note that
if time is discrete, then prescribing desired velocity ![]() is
equivalent to prescribing a desired successor state
is
equivalent to prescribing a desired successor state ![]() [Lorincz et al.(2002)]. Therefore the controller takes the form
[Lorincz et al.(2002)]. Therefore the controller takes the form
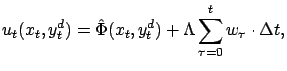 |
The above defined controller can be directly inserted into event-learning by setting
Note that the action space is still infinite.
Consequently, Theorem 3.5 is applicable.