In most applications we cannot assume that a time-independent optimal controller policy exists. To the contrary, we may have to allow the controller policy to adapt over time. In this case, we may try to require asymptotic near-optimality. This is a more realistic requirement: in many cases it can be fulfilled, e.g., by learning an approximate inverse dynamics [Fomin et al.(1997)] in parallel with E-learning. Or alternatively, the controller policy itself may be subject to reinforcement learning (with a finer state space resolution), thus defining a modular hierarchy. Another attractive solution is the application of a robust controller like the SDS controller [Szepesvári and Lorincz(1997)], which is proven to be asymptotically near-optimal. Furthermore, the SDS controller has short adaptation time, and is robust against perturbations of the environment.
As a consequence of the varying environment (recall that from the
viewpoint of E-learning, the controller policy is the part of the
environment), we cannot prove convergence any more. But we may
apply Theorem 3.3 to show that
there exists an iteration which
still finds a near-optimal event-value function. To this end, we
have to re-formulate E-learning in the generalized
![]() -MDP framework.
-MDP framework.
One can define a generalized
![]() -MDP such that its generalized
Q-learning algorithm is identical to our E-learning algorithm: Let
the state set and the transition probabilities of the E-learning
algorithm be defined by
-MDP such that its generalized
Q-learning algorithm is identical to our E-learning algorithm: Let
the state set and the transition probabilities of the E-learning
algorithm be defined by ![]() and
and ![]() , respectively. In the new
generalized
, respectively. In the new
generalized
![]() -MDP the set of states will also be
-MDP the set of states will also be ![]() , and since
an action of the learning agent is selecting a new desired state,
the set of actions
, and since
an action of the learning agent is selecting a new desired state,
the set of actions ![]() is also equal to
is also equal to ![]() . (Note that because of
this assignment, the generalized Q-value function of this model
will be exactly our event-value function
. (Note that because of
this assignment, the generalized Q-value function of this model
will be exactly our event-value function ![]() .) The definition of
the reward function
.) The definition of
the reward function ![]() is evident:
is evident:
![]() gives the reward
for arriving at
gives the reward
for arriving at ![]() from
from ![]() , when the desired state was
, when the desired state was ![]() .
Let
.
Let
![]() , independently of
, independently of ![]() ,
and let
,
and let
![]() , where
, where
![]() (see Equation 9).
(see Equation 9).
Finally, we assign the operators
![]() and
and
![]() as
as
![]() and
and
![]() .
.
The generalized Q-learning algorithm of this model uses the iteration
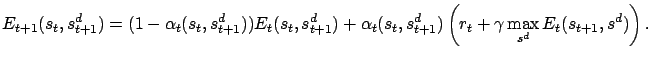 |
This is identical to the iteration defined by
[Lorincz et al.(2002)]. Here ![]() is the sequence containing the
realized states at time instant t and
is the sequence containing the
realized states at time instant t and ![]() is the sequence
containing the desired state for time instant
is the sequence
containing the desired state for time instant ![]() .
.