


Next: Decomposable priors for tree
Up: Decomposable priors and MAP
Previous: Decomposable priors and MAP
For a model 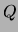 and dataset
and dataset 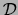 the logarithm of the
posterior
the logarithm of the
posterior
![$Pr[ Q\vert{\cal D}]$](img172.png) equals:
equals:
plus an additive constant.
The EM algorithm can be adapted to maximize the log posterior for every
fixed 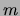 [Neal, Hinton 1999]. Indeed, by comparing with equation (5)
we see that the quantity to be maximized is now:
[Neal, Hinton 1999]. Indeed, by comparing with equation (5)
we see that the quantity to be maximized is now:
![\begin{displaymath}
E[\log Pr[ Q\vert x^{1,\ldots, N },z^{1,\ldots, N }]]\;=\;...
...Pr[Q]\;+\;
E[l_c(x^{1,\ldots, N },z^{1,\ldots, N }\vert Q)].
\end{displaymath}](img175.png) |
(9) |
The prior term does not influence the E step of the EM algorithm,
which proceeds exactly as before (cf. equation (6)). To
be able to successfully maximize the right-hand side of (9)
in the M step we require that log ![$Pr[Q]$](img176.png) decomposes into a sum of
independent terms matching the decomposition of
decomposes into a sum of
independent terms matching the decomposition of ![$E[l_c]$](img145.png) in
(7). A prior over mixtures of trees that is amenable to
this decomposition is called a decomposable prior. It will have
the following product form
in
(7). A prior over mixtures of trees that is amenable to
this decomposition is called a decomposable prior. It will have
the following product form
The first parenthesized factor in this equation represents the prior
of the tree structure 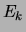 while the second factor is the prior for
parameters.
Requiring that the prior be decomposable is equivalent to making
several independence assumptions: in particular, it means that the
parameters of each tree in the mixture are independent of the
parameters of all the other trees as well as of the probability of the
mixture variable. In the following section, we show that these assumptions
are not overly restrictive, by constructing decomposable priors
for tree structures and parameters and showing that this class is rich
enough to contain members that are of practical importance.
while the second factor is the prior for
parameters.
Requiring that the prior be decomposable is equivalent to making
several independence assumptions: in particular, it means that the
parameters of each tree in the mixture are independent of the
parameters of all the other trees as well as of the probability of the
mixture variable. In the following section, we show that these assumptions
are not overly restrictive, by constructing decomposable priors
for tree structures and parameters and showing that this class is rich
enough to contain members that are of practical importance.
Next: Decomposable priors for tree
Up: Decomposable priors and MAP
Previous: Decomposable priors and MAP
Journal of Machine Learning Research
2000-10-19
![\begin{displaymath}
\log Pr[ Q ]\;+\;\sum_{x\in {\cal D}} \log Q(x)
\end{displaymath}](img174.png)
![$\displaystyle Pr[\lambda_{1,\ldots, m}] \prod_{k=1}^m
\underbrace{Pr[E_k]Pr[{\rm parameters}\vert E_k]}_{Pr[T^k]}$](img178.png)
![$\displaystyle Pr[\lambda_{1,\ldots, m}] \prod_{k=1}^m
\left[ \left( \prod_{{(u,...
...a_{uv}}\right)
\left( \prod_{v \in V}Pr[T^k_{v\vert{\rm pa}(v)}]\right)\right].$](img179.png)