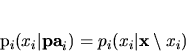Theorem 3: The procedure of an ordered Gibbs sampler
applied to a dependency network for ![]() and
and ![]() , where each
, where each
![]() is finite (and hence discrete) and each local distribution in
is finite (and hence discrete) and each local distribution in
![]() is positive, defines a Markov chain with a unique
stationary joint distribution for
is positive, defines a Markov chain with a unique
stationary joint distribution for ![]() that can be reached from any
initial state of the chain.
that can be reached from any
initial state of the chain.
Technically speaking, the procedure of Gibbs sampling
applied to an inconsistent dependency network is not itself a Gibbs
sampler, because there is no joint distribution consistent with all
the local distributions. Consequently, we call this procedure an
ordered pseudo-Gibbs sampler.
One rather disturbing property of this procedure is that it produces a
joint distribution that is likely to be inconsistent with many of the
conditional distributions used to produce it. Nonetheless, as we have
suggested and shall examine further, when each of the local
distributions of a dependency network are learned from the same data,
these distributions should be almost consistent with the joint
distribution.
Another disturbing observation is that the joint distribution obtained
will depend on the order in which the pseudo-Gibbs sampler visits the
variables. For example, consider the dependency network with the
structure
![]() , saying that
, saying that ![]() depends on
depends on ![]() but
but ![]() does not depend on
does not depend on ![]() . If we draw sample-pairs
. If we draw sample-pairs
![]() --that is,
--that is, ![]() and then
and then ![]() --then the resulting
stationary distribution will have
--then the resulting
stationary distribution will have ![]() and
and ![]() dependent. In
contrast, if we draw sample-pairs
dependent. In
contrast, if we draw sample-pairs ![]() , then the resulting
stationary distribution will have
, then the resulting
stationary distribution will have ![]() and
and ![]() independent. Due to
the near consistency of the local distributions, however, the joint
distributions obtained from different orderings will be close. If we
indeed discover the dependency-network structure
independent. Due to
the near consistency of the local distributions, however, the joint
distributions obtained from different orderings will be close. If we
indeed discover the dependency-network structure
![]() in practice, then
in practice, then ![]() and
and ![]() must be ``almost'' independent.
Given a graphical model for a domain and an ordered Gibbs sampler that
extracts a joint distribution from that model, we can apply the rules
of probability to this joint distribution to answer probabilistic
queries. Alternatively, we can apply Algorithm 1 directly to a given
dependency network. Such an application may yield different answers
than those computed from the joint distribution obtained from the
dependency network, but can be justified heuristically due to near
consistency. In Sections 3.3 and 3.4, we
examine the issue of near consistency more carefully. In the
remainder of this section, we mention two basic properties of
dependency networks.
First, let us consider the distributions that can be represented by a
general dependency-network structure. Unlike the situation for
consistent dependency networks, a general dependency-network structure
and a Markov network structure with the same adjacencies do not
represent the same distributions. In fact, a dependency network with
a given structure defines a larger set of distributions than a Markov
network with the same adjacencies. As an example, consider the
dependency-network structure
must be ``almost'' independent.
Given a graphical model for a domain and an ordered Gibbs sampler that
extracts a joint distribution from that model, we can apply the rules
of probability to this joint distribution to answer probabilistic
queries. Alternatively, we can apply Algorithm 1 directly to a given
dependency network. Such an application may yield different answers
than those computed from the joint distribution obtained from the
dependency network, but can be justified heuristically due to near
consistency. In Sections 3.3 and 3.4, we
examine the issue of near consistency more carefully. In the
remainder of this section, we mention two basic properties of
dependency networks.
First, let us consider the distributions that can be represented by a
general dependency-network structure. Unlike the situation for
consistent dependency networks, a general dependency-network structure
and a Markov network structure with the same adjacencies do not
represent the same distributions. In fact, a dependency network with
a given structure defines a larger set of distributions than a Markov
network with the same adjacencies. As an example, consider the
dependency-network structure
![]() . In a simple experiment, we sampled local distributions for this
structure from a uniform distribution. We then computed the
stationary distribution of the Markov chain defined by a pseudo-Gibbs
sampler with variable order
. In a simple experiment, we sampled local distributions for this
structure from a uniform distribution. We then computed the
stationary distribution of the Markov chain defined by a pseudo-Gibbs
sampler with variable order ![]() . In all runs, we found
that
. In all runs, we found
that ![]() and
and ![]() were conditionally dependent given
were conditionally dependent given ![]() in
the stationary distribution. In a Markov network with the same
adjacencies,
in
the stationary distribution. In a Markov network with the same
adjacencies, ![]() and
and ![]() must be conditionally independent given
must be conditionally independent given
![]() .
Second, let us consider a simple necessary condition for consistency.
We say that a dependency network for
.
Second, let us consider a simple necessary condition for consistency.
We say that a dependency network for ![]() is bi-directional if
is bi-directional if
![]() is a parent of
is a parent of ![]() if and only if
if and only if ![]() is a parent of
is a parent of ![]() ,
for all
,
for all ![]() and
and ![]() in
in ![]() . In addition, let
. In addition, let ![]() be the
be the
![]() parent of node
parent of node ![]() . We say that a consistent dependency
network is minimal if and only if, for every node
. We say that a consistent dependency
network is minimal if and only if, for every node ![]() and for
every parent
and for
every parent ![]() ,
, ![]() is not independent of
is not independent of ![]() given the
remaining parents of
given the
remaining parents of ![]() . With these definitions, we have the
following theorem, proved in the Appendix.
. With these definitions, we have the
following theorem, proved in the Appendix.
Theorem 4: A minimal consistent dependency network for
a positive distribution ![]() must be bi-directional.
must be bi-directional.