Event-learning can integrate the benefits of controllers into reinforcement learning. This is illustrated in the experiment below (see also [Lorincz et al.(2002)]).
From the viewpoint of the event-value function, we may expect in perturbed environments that possibly large changes in the environment are reduced by the robust controller. This means that a fixed event-value function could be close to optimal for considerable changes in the environment.
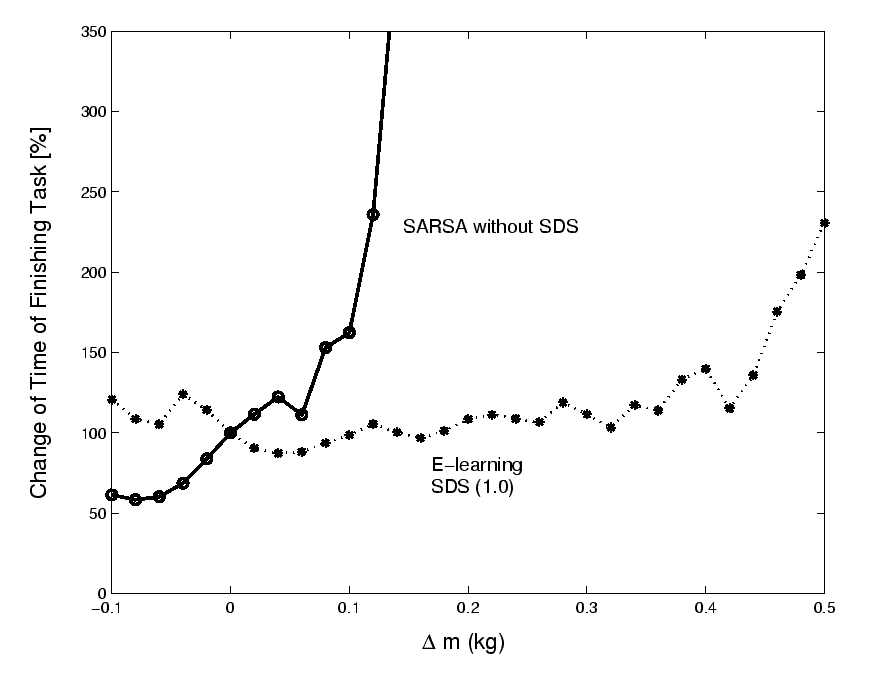
To examine this behavior, event-learning and the well-known SARSA method was optimized for the default mass of the small arm.9 After switching learning off, the mass parameter was perturbed, which modified the dynamics of the system. Figure 4 depicts the results of the computer simulations. The figure shows the average task completion time for the two methods as a function of the mass change. The horizontal axis of the figure shows the change of the mass of the second link (in kilograms). With lighter (heavier) mass, the state-action policy finishes the task sooner (later). Beyond about 0.1 kg (approx. a 25%) mass increase sharp deterioration takes place and performance of the state-action policy drops suddenly.
In contrast, E-learning with SDS starts to deteriorate only at around doubled mass. Small changes of the mass do not influence the task completion time significantly.
|