We therefore propose to keep in memory a table of
![]() .
Moreover, to update this variable, we can see that
.
Moreover, to update this variable, we can see that
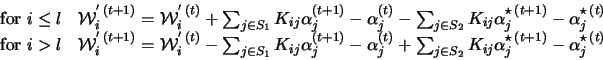
For the computation of
![]() ,
we can use the following trick:
,
we can use the following trick:
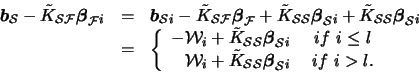
With these two ideas, one can reduce considerably the computational time:
instead of computing all the lines of the matrix K, one can compute only
the lines corresponding to the variables in
![]() .
.
Since we only need these lines for the computations, and since it quickly becomes intractable for large problems to keep the whole matrix Kin memory (the size of the matrix being quadratic with respect to the number of examples), it is interesting to implement a cache that keeps in memory the lines of K that corresponds to the most used variables instead of recomputing them at each iteration.