


Next: MAP estimation by the
Up: Learning with Mixtures of
Previous: Learning mixtures of trees
Decomposable priors and MAP estimation for mixtures of trees
The Bayesian learning framework combines information obtained from
direct observations with prior knowledge about the model, when the
latter is represented as a probability distribution. The object of
interest of Bayesian analysis is the posterior distribution over
the models given the observed data,
![$Pr[ Q\vert{\cal D}]$](img172.png) , a quantity
which can rarely be calculated explicitly. Practical methods for
approximating the posterior include choosing a single
maximum a posteriori (MAP) estimate, replacing the continuous
space of models by a finite set
, a quantity
which can rarely be calculated explicitly. Practical methods for
approximating the posterior include choosing a single
maximum a posteriori (MAP) estimate, replacing the continuous
space of models by a finite set 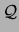 of high posterior
probability [Heckerman, Geiger, Chickering
1995], and expanding the posterior
around its mode(s) [Cheeseman, Stutz 1995].
Finding the local maxima (modes) of the distribution
is a necessary step in all the above methods and is our primary concern
in this section. We demonstrate that maximum a posteriori modes can be found
as efficiently as maximum likelihood modes, given a particular choice of
prior. This has two consequences: First, it makes approximate Bayesian
averaging possible. Second, if one uses a non-informative prior,
then MAP estimation is equivalent to Bayesian smoothing, and
represents a form of regularization. Regularization is particularly
useful in the case of small data sets in order to prevent overfitting.
of high posterior
probability [Heckerman, Geiger, Chickering
1995], and expanding the posterior
around its mode(s) [Cheeseman, Stutz 1995].
Finding the local maxima (modes) of the distribution
is a necessary step in all the above methods and is our primary concern
in this section. We demonstrate that maximum a posteriori modes can be found
as efficiently as maximum likelihood modes, given a particular choice of
prior. This has two consequences: First, it makes approximate Bayesian
averaging possible. Second, if one uses a non-informative prior,
then MAP estimation is equivalent to Bayesian smoothing, and
represents a form of regularization. Regularization is particularly
useful in the case of small data sets in order to prevent overfitting.
Subsections
Next: MAP estimation by the
Up: Learning with Mixtures of
Previous: Learning mixtures of trees
Journal of Machine Learning Research
2000-10-19