


Next: Random bars, small data
Up: Structure identification
Previous: Structure identification
For the first structure identification experiment, we generated a mixture
of  trees over 30 variables with each vertex having
trees over 30 variables with each vertex having  values.
The distribution of the choice variable
values.
The distribution of the choice variable 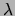 as well as each tree's
structure and parameters were sampled at random. The mixture was used
to generate 30,000 data points that were used as a training set for
a MIXTREE algorithm. The initial model had components but
otherwise was random. We compared the structure of the learned model with
the generative model and computed the likelihoods of both the learned and
the original model on a test dataset consisting of 1000 points.
The algorithm was quite successful at identifying the original trees:
out of 10 trials, the algorithm failed to identify correctly only 1 tree
in 1 trial. Moreover, this result can be accounted for by sampling
noise; the tree that wasn't identified had a mixture coefficient
of only
as well as each tree's
structure and parameters were sampled at random. The mixture was used
to generate 30,000 data points that were used as a training set for
a MIXTREE algorithm. The initial model had components but
otherwise was random. We compared the structure of the learned model with
the generative model and computed the likelihoods of both the learned and
the original model on a test dataset consisting of 1000 points.
The algorithm was quite successful at identifying the original trees:
out of 10 trials, the algorithm failed to identify correctly only 1 tree
in 1 trial. Moreover, this result can be accounted for by sampling
noise; the tree that wasn't identified had a mixture coefficient
of only  . The difference between the log likelihood
of the samples of the generating model and the approximating model was
0.41 bits per example.
. The difference between the log likelihood
of the samples of the generating model and the approximating model was
0.41 bits per example.
Next: Random bars, small data
Up: Structure identification
Previous: Structure identification
Journal of Machine Learning Research
2000-10-19