

Next: Data Visualization
Up: Collaborative Filtering
Previous: Evaluation Criteria and Experimental
Results
Table 3 shows the accuracy of recommendations for dependency networks
and Bayesian networks across the various protocols and three datasets.
For a comparison, we also measured the accuracy of recommendation
lists produced by a Bayesian network with no arcs (baseline model).
This model recommends items based on their overall popularity,
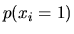 . A score in boldface corresponds to a statistically
significant winner. We use ANOVA (e.g., McClave and Dietrich,
1988) with
. A score in boldface corresponds to a statistically
significant winner. We use ANOVA (e.g., McClave and Dietrich,
1988) with 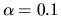 to test for statistical
significance. When the difference between two scores in the same
column exceed the value of RD (required difference), the difference is
significant.
As in the case of density estimation, we see from the table
that Bayesian networks are more accurate than dependency networks, but
only slightly so. In particular, the ratio of (cfaccuracy(BN) -
cfaccuracy(DN)) to (cfaccuracy(BN) - cfaccuracy(Baseline)) averages
to test for statistical
significance. When the difference between two scores in the same
column exceed the value of RD (required difference), the difference is
significant.
As in the case of density estimation, we see from the table
that Bayesian networks are more accurate than dependency networks, but
only slightly so. In particular, the ratio of (cfaccuracy(BN) -
cfaccuracy(DN)) to (cfaccuracy(BN) - cfaccuracy(Baseline)) averages
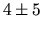 percent across the datasets and protocols. As before,
the differences are probably due to the fact that dependency networks
are less statistically efficient than Bayesian networks.
Tables 4 and 5 compare the two methods with the remaining criteria.
Here, dependency networks are a clear winner. They are significantly
faster at prediction--sometimes by almost an order of magnitude--and
require substantially less time and memory to learn. Overall,
Bayesian networks are slightly more accurate but much less attractive
from a computational perspective.
percent across the datasets and protocols. As before,
the differences are probably due to the fact that dependency networks
are less statistically efficient than Bayesian networks.
Tables 4 and 5 compare the two methods with the remaining criteria.
Here, dependency networks are a clear winner. They are significantly
faster at prediction--sometimes by almost an order of magnitude--and
require substantially less time and memory to learn. Overall,
Bayesian networks are slightly more accurate but much less attractive
from a computational perspective.
Table 3:
CF accuracy for the MS.COM, Nielsen, and MSNBC datasets.
Higher scores indicate better performance. Statistically significant
winners are shown in boldface.
| |
MS.COM |
| Algorithm |
Given2 |
Given5 |
Given10 |
AllBut1 |
| BN |
53.18 |
52.48 |
51.64 |
66.54 |
| DN |
52.68 |
52.54 |
51.48 |
66.60 |
| RD |
0.30 |
0.73 |
1.62 |
0.34 |
| Baseline |
43.37 |
39.34 |
39.32 |
49.77 |
| |
Nielsen |
| Algorithm |
Given2 |
Given5 |
Given10 |
AllBut1 |
| BN |
24.99 |
30.03 |
33.84 |
45.55 |
| DN |
24.20 |
29.71 |
33.80 |
44.30 |
| RD |
0.32 |
0.40 |
0.65 |
0.72 |
| Baseline |
12.65 |
12.72 |
12.92 |
13.59 |
| |
MSNBC |
| Algorithm |
Given2 |
Given5 |
Given10 |
AllBut1 |
| BN |
40.34 |
34.20 |
30.39 |
49.58 |
| DN |
38.84 |
32.53 |
30.03 |
48.05 |
| RD |
0.35 |
0.77 |
1.54 |
0.39 |
| Baseline |
28.73 |
20.58 |
14.93 |
32.94 |
Table 4:
Number of predictions per second for the MS.COM, Nielsen, and MSNBC datasets.
| |
MS.COM |
| Algorithm |
Given2 |
Given5 |
Given10 |
AllBut1 |
| BN |
3.94 |
3.84 |
3.29 |
3.93 |
| DN |
23.29 |
19.91 |
10.20 |
23.48 |
| |
Nielsen |
| Algorithm |
Given2 |
Given5 |
Given10 |
AllBut1 |
| BN |
22.84 |
21.86 |
20.83 |
23.53 |
| DN |
36.17 |
36.72 |
34.21 |
37.41 |
| |
MSNBC |
| Algorithm |
Given2 |
Given5 |
Given10 |
AllBut1 |
| BN |
7.21 |
6.96 |
6.09 |
7.07 |
| DN |
11.88 |
11.03 |
8.52 |
11.80 |
Table 5:
Computational resources for model learning.
| |
MS.COM |
| Algorithm |
Memory (Meg) |
Learn Time (sec) |
| BN |
42.4 |
144.65 |
| DN |
5.3 |
98.31 |
| |
Nielsen |
| Algorithm |
Memory (Meg) |
Learn Time (sec) |
| BN |
3.3 |
7.66 |
| DN |
2.1 |
6.47 |
| |
MSNBC |
| Algorithm |
Memory (Meg) |
Learn Time (sec) |
| BN |
43.0 |
105.76 |
| DN |
3.7 |
96.89 |
Next: Data Visualization
Up: Collaborative Filtering
Previous: Evaluation Criteria and Experimental
Journal of Machine Learning Research,
2000-10-19