

Next: Datasets
Up: Dependency Networks for Inference,
Previous: Related Work
Collaborative Filtering
We now turn our attention to collaborative filtering (CF), the task of
predicting preferences. Examples of this task include predicting what
movies a person will like based on his or her ratings of movies seen,
predicting what news stories a person is interested in based on other
stories he or she has read, and predicting what web pages a person
will go to next based on his or her history on the site. Another
important application in the burgeoning area of e-commerce is
predicting what products a person will buy based on products he or she
has already purchased and/or dropped into his or her shopping basket.
Collaborative filtering was introduced by Resnick, Iacovou, Suchak,
Bergstrom, and Riedl (1994) as both the task of
predicting preferences and a class of algorithms for this task. The
class of algorithms they described was based on the informal
mechanisms people use to understand their own preferences. For
example, when we want to find a good movie, we talk to other people
that have similar tastes and ask them what they like that we haven't
seen. The type of algorithm introduced by Resnik et al. (1994),
sometimes called a memory-based algorithm, does something
similar. Given a user's preferences on a series of items, the
algorithm finds similar users in a database of stored preferences. It
then returns some weighted average of preferences among these users on
items not yet rated by the original user.
As done in Breese, Heckerman, and Kadie (1998), let us
concentrate on the application of collaborative filtering--that
is, preference prediction. In their paper, Breese et al. (1998)
describe several CF scenarios, including binary versus non-binary
preferences and implicit versus explicit voting. An example of
explicit voting would be movie ratings provided by a user. An example
of implicit voting would be knowing only whether a person has or has
not purchased a product. Here, we concentrate on one scenario
important for e-commerce: implicit voting with binary
preferences--for example, the task of predicting what products a
person will buy, knowing only what other products they have purchased.
A simple approach to this task, described in Breese et al. (1998), is
as follows. For each item (e.g., product), define a variable with two
states corresponding to whether or not that item was preferred (e.g.,
purchased). We shall use ``0'' and ``1'' to denote not preferred and
preferred, respectively. Next, use the dataset of ratings to learn a
Bayesian network for the joint distribution of these variables
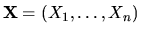 . The preferences of each user constitutes a
case in the learning procedure. Once the Bayesian network is
constructed, make predictions as follows. Given a new user's
preferences
. The preferences of each user constitutes a
case in the learning procedure. Once the Bayesian network is
constructed, make predictions as follows. Given a new user's
preferences 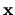 , use the Bayesian network to estimate
, use the Bayesian network to estimate
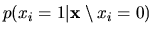 for each product
for each product 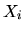 not purchased. That is,
estimate the probability that the user would have purchased the item
had we not known he did not. Then, return a list of recommended
products--among those that the user did not purchase--ranked by these
estimates.
Breese et al. (1998) show that this approach outperforms memory-based
and cluster-based methods on several implicit rating datasets.
Specifically, the Bayesian-network approach was more accurate and
yielded faster predictions than did the other methods.
What is most interesting about this algorithm in the context of this
paper is that only estimates of
are needed to produce the recommendations. In particular, these
estimates may be obtained by a direct lookup in a dependency
network:
not purchased. That is,
estimate the probability that the user would have purchased the item
had we not known he did not. Then, return a list of recommended
products--among those that the user did not purchase--ranked by these
estimates.
Breese et al. (1998) show that this approach outperforms memory-based
and cluster-based methods on several implicit rating datasets.
Specifically, the Bayesian-network approach was more accurate and
yielded faster predictions than did the other methods.
What is most interesting about this algorithm in the context of this
paper is that only estimates of
are needed to produce the recommendations. In particular, these
estimates may be obtained by a direct lookup in a dependency
network:
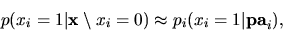 |
(8) |
where 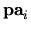 is the instance of
is the instance of 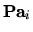 consistent with
consistent with 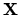 . Thus,
dependency networks are a natural model class on which to base CF
predictions. In the remainder of this section, we compare this
approach with that based on Bayesian networks for datasets containing
binary implicit ratings.
. Thus,
dependency networks are a natural model class on which to base CF
predictions. In the remainder of this section, we compare this
approach with that based on Bayesian networks for datasets containing
binary implicit ratings.
Subsections
Next: Datasets
Up: Dependency Networks for Inference,
Previous: Related Work
Journal of Machine Learning Research,
2000-10-19