Vapnik [15] has proposed a method to solve regression problems using support vector machines. It has yielded excellent performance on many regression and time series prediction problems (see for instance [10] or [2]). This paper proposes an efficient implementation of SVMs for large-scale regression problems. Let us first recall how it works.
Given a training set of l examples
![]() with
with
![]() and
and
![]() ,
where E is an Euclidean space
with a scalar product denoted
,
where E is an Euclidean space
with a scalar product denoted
![]() ,
we want to estimate the
following linear regression:
,
we want to estimate the
following linear regression:
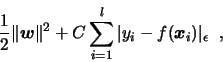
Written as a constrained optimization problem, it amounts to minimizing
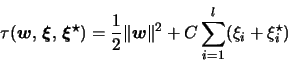
To generalize to non-linear regression, we replace the dot product
with a kernel ![]() .
Then, introducing Lagrange multipliers
.
Then, introducing Lagrange multipliers
![]() and
and
![]() ,
the optimization
problem can be stated as:
,
the optimization
problem can be stated as:
Minimize the objective function
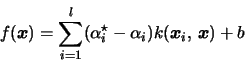
Solving the minimization problem (3) under the constraints (4) and (5) needs resources on the order of l2 and is thus difficult for problems with large l.
In this paper, we propose a method to solve such problems efficiently using a decomposition algorithm similar to the one proposed by Joachims [5] in the context of classification problems. In the next section, we give the general algorithm and explain in more detail each of its main steps and how they differ from other published algorithms, as well as a discussion on convergence and on some important implementation issues, such as a way to efficiently handle the kernel matrix computation. In the experiment section, we compare this new algorithm on small and large datasets to Nodelib, another SVM algorithm for large-scale regression problems proposed by Flake and Lawrence [3], then show how the size of the internal memory allocated to the resolution of the problem is related to the time needed to solve it, and finally how our algorithm scales with respect to l.