
Next: Results
Up: Collaborative Filtering
Previous: Datasets
We have found the following three criteria for collaborative filtering
to be important: (1) the accuracy of the recommendations, (2)
prediction time--the time it takes to create a recommendation list
given what is known about a user, and (3) the computational resources
needed to build the prediction models. We measure each of these
criteria in our empirical comparison. In the remainder of this
section, we describe our evaluation criterion for accuracy.
Our criterion attempts to measure a user's expected utility for a list
of recommendations. Of course, different users will have different
utility functions. The measure we introduce provides what we believe
to be a good approximation across many users.
The scenario we imagine is one where a user is shown a ranked list of
items and then scans that list for preferred items starting from the
top. At some point, the user will stop looking at more items. Let
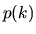 denote the probability that a user will examine the
denote the probability that a user will examine the 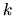 th item
on a recommendation list before stopping his or her scan, where the
first position is given by
th item
on a recommendation list before stopping his or her scan, where the
first position is given by 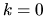 . Then, a reasonable criterion is
. Then, a reasonable criterion is
where 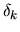 is 1 if the item at position is preferred and 0
otherwise. To make this measure concrete, we assume that is an
exponentially decaying function:
is 1 if the item at position is preferred and 0
otherwise. To make this measure concrete, we assume that is an
exponentially decaying function:
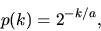 |
(9) |
where 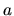 is the ``half-life'' position--the position at which an
item will be seen with probability 0.5. In our experiments, we use
is the ``half-life'' position--the position at which an
item will be seen with probability 0.5. In our experiments, we use
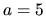 .
In one possible implementation of this approach, we could show
recommendations to a series of users and ask them to rate them as
``preferred'' or ``not preferred''. We could then use the average of
cfaccuarcy
.
In one possible implementation of this approach, we could show
recommendations to a series of users and ask them to rate them as
``preferred'' or ``not preferred''. We could then use the average of
cfaccuarcy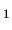 (list) over all users as our criterion. Because this
method is extremely costly, we instead use an approach that uses only
the data we have. In particular, as already described, we randomly
partition a dataset into a training set and a test set. Each case in
the test set is then processed as follows. First, we randomly
partition the user's preferred items into input and
measurement sets. The input set is fed to the CF model, which in
turn outputs a list of recommendations. Finally, we compute our
criterion as
(list) over all users as our criterion. Because this
method is extremely costly, we instead use an approach that uses only
the data we have. In particular, as already described, we randomly
partition a dataset into a training set and a test set. Each case in
the test set is then processed as follows. First, we randomly
partition the user's preferred items into input and
measurement sets. The input set is fed to the CF model, which in
turn outputs a list of recommendations. Finally, we compute our
criterion as
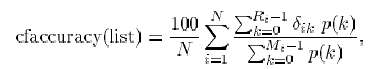 |
(10) |
where 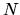 is the number of users in the test set,
is the number of users in the test set, 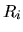 is the number
of items on the recommendation list for user
is the number
of items on the recommendation list for user 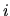 ,
, 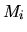 is the number
of preferred items in the measurement set for user , and
is the number
of preferred items in the measurement set for user , and
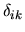 is 1 if the th item in the recommendation list for
user is preferred in the measurement set and 0 otherwise. The
denominator in Equation 10 is a per-user normalization
factor. It is the utility of a list where all preferred items are at
the top. This normalization allows us to more sensibly combine scores
across measurement sets of different size.
We performed several experiments reflecting differing numbers of
ratings available to the CF engines. In the first protocol, we
included all but one of the preferred items in the input set. We term
this protocol all but 1. In additional experiments, we placed
2, 5, and 10 preferred items in the input sets. We call these
protocols given 2, given 5, and given 10.
The all but 1 experiments measure the algorithms' performance
when given as much data as possible from each test user. The various
given experiments look at users with less data available, and
examine the performance of the algorithms when there is relatively
little known about an active user. When running the given m
protocols, if an input set for a given user had less than
is 1 if the th item in the recommendation list for
user is preferred in the measurement set and 0 otherwise. The
denominator in Equation 10 is a per-user normalization
factor. It is the utility of a list where all preferred items are at
the top. This normalization allows us to more sensibly combine scores
across measurement sets of different size.
We performed several experiments reflecting differing numbers of
ratings available to the CF engines. In the first protocol, we
included all but one of the preferred items in the input set. We term
this protocol all but 1. In additional experiments, we placed
2, 5, and 10 preferred items in the input sets. We call these
protocols given 2, given 5, and given 10.
The all but 1 experiments measure the algorithms' performance
when given as much data as possible from each test user. The various
given experiments look at users with less data available, and
examine the performance of the algorithms when there is relatively
little known about an active user. When running the given m
protocols, if an input set for a given user had less than 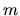 preferred items, the case was eliminated from the evaluation. Thus
the number of trials evaluated under each protocol varied.
All experiments were performed on a 300 MHz Pentium II with 128 MB of
memory running the Windows NT 4.0 operating system.
preferred items, the case was eliminated from the evaluation. Thus
the number of trials evaluated under each protocol varied.
All experiments were performed on a 300 MHz Pentium II with 128 MB of
memory running the Windows NT 4.0 operating system.
Next: Results
Up: Collaborative Filtering
Previous: Datasets
Journal of Machine Learning Research,
2000-10-19