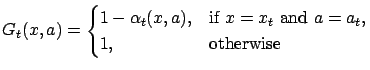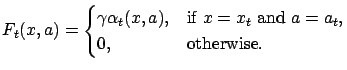It is an easy consequence of Theorem A.1 that under appropriate conditions, the Q-learning algorithm is convergent.
Consider the substitution
![]() ,
,
![]() and
and
![]() . Furthermore, let the
randomized approximate dynamic programming operator sequence
defined by
. Furthermore, let the
randomized approximate dynamic programming operator sequence
defined by
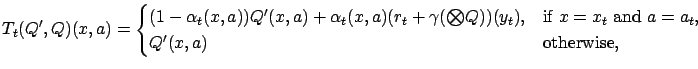 |
Finally, let
Condition (4) of Theorem A.1 trivially holds, while
conditions (1) and (2) are implied by the definition of ![]() and
the non-expansion property of
and
the non-expansion property of
![]() . Finally, condition (3) is a
consequence of assumption (3) and the definition of
. Finally, condition (3) is a
consequence of assumption (3) and the definition of ![]() .
.
Applying Theorem A.1 proves the statement.
![]()